DDD 11 In Review

This past Saturday 3rd September 2016, the 11th DDD (DeveloperDeveloperDeveloper) conference was held at Microsoft’s UK HQ in Reading. Although I’ve been a number of DDD events in recent years, this was my first time at the original DDD event (aka Developer Day aka DDD Reading) which spawned all of the other localised DDD events.

After travelling the evening before and staying overnight in a hotel in Swindon, I set off bright and early to make the 1 hour drive to Reading. After arriving and checking in, collecting my badge along the way, it was time to grab a coffee and one of the hearty breakfast butties supplied. Coffee and sausage sandwich consumed, it was time to familiarise myself with the layout of the rooms. There were 4 parallel tracks of talks, and there had also been a room change from the printed agendas that we received upon checking in. After finding the new rooms, and consulting my agenda sheet it was time for me to head off to the first talk of the day. This was Gary Short’s “How to make your bookie cry”.
With a promise of showing us all how to make money on better exchanges and also how to “beat the bookie”, Gary’s talk was an interesting proposition and commanded a full room of attendees. Gary’s session is all about machine learning and how data science can help us do many things, including making predictions on horse races in an attempt to beat the bookie. Gary starts by giving the fundamental steps of machine learning – Predict – Measure – Analyze – Adjust. But, we start with measure as we need some data to set us off on our way.

Gary states that bookie odds in the UK are expressed as fractions and that this hides the inherent probabilities of each horse winning in a given race. Bookies ultimately will make a profit on a given race as the probabilities of all of the horses add up to more than 1! So, we can beat the bookie if we build a better data model. We do this with data. We can purchase horse racing data, which means we’re already at a loss given the cost of the data, or we can screen scrape it from a sports website, such as BBC Sport. Gary shows us a demo of some Python code used to scrape the data from the BBC website. He states that Python is one of two “standard” languages used within Data Science, the other language being R. After scraping a sufficiently sized dataset over a number of days, we can analyze that data by building a Logistic Regression Model. Gary shows how to use the R language to achieve this, ultimately giving us a percentage likelihood of a given horse winning a new race based upon its past results, its weight and the jockey riding it.
Gary next explains a very important consideration within Data Science known as The Turkey Paradox. You’re a turkey on a farm, you have to decide if today you’re going to get fed or go to market. If your data model only has the data points of being fed at 9am for the last 500 days, you’ll never be able to predict if today is the day you go to market - as it’s never happened before. There is a solution to this - it’s called Active Learning or Human in the Loop learning. But. It turns out humans are not very good at making decisions.
Gary next explains the differences between System 1 and System 2 thinking. System 2 is very deliberate actions - you think first and deliberately make the action. System 1 is reflexive - when you put your hand on a hot plate, you pull it away without even thinking. It uses less of the brain. System 1 is our “lizard brain” from the days when we were cavemen. And it takes precedence over System 2. Gary talks about the types of System 1 thinking. There’s Cognitive Dissonance – holding onto a belief in the face of mounting contrary evidence. Another is bait-and-switch – substituting a less favourable option after being “baited” with a more favourable one, and yet another type is the “halo effect” – beautiful things are believed to be desirable. We need to ensure that, when using human-in-the-loop additions to our data model, we don’t fall foul of these problems.

Next, we explore Bayes’ theorem. A theorem describing how the conditional probability of each of a set of possible causes for a given observed outcome can be computed from knowledge of the probability of each cause and the conditional probability of the outcome of each cause. Gary uses this theorem over our horse racing data model to demonstrate Bayes inference using prior probabilities to predict future ones. This is using the raw scraped data, with no human-in-the-loop additions, but we can add our own additions which become prior probabilities and can be used to compute further probabilities using Bayes theorem.
Gary concludes that, once we’ve acquired, trained and analyzed our data model, we can beat the bookie if our odds are shorter than the bookie’s. Another way, it not to beat the bookie at all! We can make money simply by beating other gamblers. We can do this using betting exchanges - backing and laying bets and getting other gamblers to bet against your prediction of the outcome of an event. Finally, you can also profit from “trading arbitrage” – whereby the clever placing of bets when two different bookies have the same event outcome at two different odds can produce a profit from the difference between those odds.

After a short coffee break, it was onto the second session of the day, which was Ali Kheyrollahi’s “Microservice Architecture at ASOS”. Ali first explains the background of the ASOS company where he works. They’re a Top 35 online retailer, within the Top 10 of online fashion retailers, they have a £1.5 billion turnover and, for their IT, they process around 10000 requests per second. Ali states that ASOS is at it’s core a technology company, and it’s through this that they succeed with IT – you’ve got to be a great tech business, not just a great tech function. Tech drives the agenda and doesn’t chase the rest of the business.
Ali asks “Why Microservices?” and states that it’s really about scaling the people within the business, not just the tech solution. Through decoupling the entire solution, you decentralise decision making. Core services can be built in their own tech stack by largely independent teams. It allows fast and frequent releases and deployments of separate services. You reduce the complexity of each service, although, Ali does admit that you will, overall, increase the complexity of the overall solution.
The best way achieve all of this is through committed people. Ali shows a slide which mentions the German army’s “Auftragstaktik” which is method of commanding in which the commander gives subordinate leaders a specific mission, a timescale of achievement and the forces required to meet the goal, however, the individual leaders are free to engage their own subordinates services are they see fit. It’s about telling them how to think, not what to think. He also shares a quote from “The Little Prince” that embodies this thinking, “If you wish to build a ship, do not divide the men into teams and send them to the forest to cut wood. Instead, teach them to long for the vast and endless sea.” If you wish to succeed with IT and Microservices in particular, you have to embrace this culture. Ali states that with a “triangle” of domain modelling, people and a good operation model, this really all equals successful architecture.
Ali hands over to his colleague Dave Green who talks about how ASOS, like many companies, started with a legacy monolithic system. And like most others, they had to work with this system as it stood – they couldn’t just throw it out and start over again it was after all handling nearly £1 billion in transaction per year, however, despite fixing some of the worst performance problems of the monolithic system, they ultimately concluded that it would be easier and cheaper to build a new system than to fix the old one. Dave explains how they have a 2 tier IT system within the company – there’s the enterprise domain and the digital domain. The enterprise domain is primarily focused on buy off-the-shelf software to run the Finance, HR and other aspects of the business. They’re project lead. Then there’s the digital domain, much more agile, product lead and focused on building solutions rather than buying them.
Ali state how ASOS is a strategic partner with Microsoft and is heavily invested in cloud technology, specifically Microsoft’s Azure platform. He suggests that ASOS may well be the largest single Azure user this side of the Atlantic ocean! He talks about the general tech stack, which is C# and using TeamCity for building and Octopus Deploy for deployment. There’s also lots of other tech used, however, and other teams are making use of Scala, R, and other languages where it’s appropriate. The database stack is primarily SQL Server, but they also use Redis and MongoDB.

Ali talks about one of the most important parts of building a distributed micro service based solution – the LMA stack – that’s Logging, Monitoring and Altering. All micro services are build to adhere to some core principles. All queries and commands use HTTP API, but there’s no message brokers or ESB-style pseudo microservices. They exist outside of the services, but never inside. For the logging, Ali states how logging is inherent within all parts of every service, however, they do most logging and instrumentation whenever there is any kind of I/O – network, file system or database reads and writes. As part of their logging infrastructure, they use Woodpecker, which is a queue and topic monitoring solution for Azure Service Bus.
All of the logs and Woodpecker output is fed into a Log collector and processor. They don’t use LogStash for this, which is a popular component, but instead use ConveyorBelt. This play better with Azure and some of the Azure-specific implementation and storage of certain log data. Both LogStash and ConveyorBelt, however, have the same purpose – to quickly collect and push log data to ElasticSearch. From here, they use the popular Kibana product to visualise that data. So rather than a ELK stack (ElasticSearch, LogStash, Kibana), it’s a ECK stack (ElasticSearch, ConveyorBelt, Kibana).
Ali concludes his talk by discussing lessons learnt. He says, if you’re in the cloud - build for failure as the cloud is a jungle! Network latency and failures add up so it's important to understand and optimize time from the user to the data. With regard to operating in the cloud in general, Ignore the hype - trust no one. Test, measure, adopt/drop, monitor and engage with your provider. It's difficult to manage platform costs, so get automation and monitoring of the cloud infrastructure to prevent developers creating erroneous VM’s that they forget to switch off! Finally, distributed computing is hard, geo-distribution is even harder. Expect to roll up your sleeves. Maturity in areas can be low and is changing rapidly.

After Ali’s talk there was another coffee break in the communal area before we all headed off to the 3rd session of the day. For me, this was Mark Rendle’s “Somewhere over the Windows”. Mark’s talk revolved around .NET core and it’s ability to run cross-platform. He opened by suggesting that, being the rebel he is, the thought he’d come to Microsoft UK HQ and give a talk about how to move away from Windows and onto a Linux OS!
Mark starts by saying that Window is great, and a lot of the intrinsic parts of Windows that we use as developers, such as IIS and .NET are far too deeply tied into a specific version of Windows. Mark gives the example that IIS has only just received support for HTTP2, but that it’s only the version of IIS contained within the not-yet-released Windows Server 2016 that’ll support it. He says that, unfortunately, Windows is stuck in a rut for around 4 years, and every 4 years Microsoft’s eco-system has to try to catch up with everybody else with a new version of Windows.
.NET Core will help us as developers to break away from this getting stuck in a rut. .NET Core runs on Windows, Linux and Mac OSX. It’s self-contained so that you can simply ship a folder containing your application’s files and the .NET core runtime files, and it’ll all “just work”. Mark mentions ASP.NET Core, which actually started the whole “core” thing at Microsoft and they then decided to go for it with everything else. ASP.NET Core is a ground-up rewrite, merges MVC and Web API into a unified whole and has it’s own built-in web server, Kestrel which is incredibly fast. Mark says how his own laptop has now been running Linux Mint for the last 1.5 years and how he’s been able to continue being a “.NET developer” despite not using Windows as his main, daily OS.
Mark talks about how, in this brave new world, we’re going to have to get used to the CLI – Command Line Interface. Although some graphical tooling exists, the slimmed down .NET core will take us back to the days of developing and creating our projects and files from the CLI. Mark says he uses Guake as his CLI of choice on his Linux Mint install. Mark talks about Yeoman - the scaffolding engine used for ASP.NET Core bootstrap. It’s a node package, and mark admits that pretty much all web development these days, irrespective of platform, is pretty much dependent on node and it’s npm package manager. Even Microsoft’s own TypeScript is a node package. Mark shows creating a new ASP.NET Core application using Yeoman. The yeoman script creates the files/folders, does a dotnet restore command to restore nuget packages then does a bower restore to restore front-end (i.e. JavaScript) packages from Bower.
Mark says that tooling was previously an issue with developing on Linux, but it’s now better. There’s Visual Studio 2015 Update 3 for Windows only, but there's also Project Rider and Xamarin Studio which can run on Linux in which .NET Core code can be developed. For general editors, there’s VS Code, Atom, SubLime Text 3, Vim or Emacs! VS Code and Atom are both based on Electron.
Mark moves on to discuss logging in an application. In .NET Core it’s a first class citizen as it contains a LoggerFactory. It’ll write to STDOUT and STDERROR and therefore it works equally well on Windows and Linux. This is an improvement over the previous types of logging we could achieve which would often result in writing to Windows-only log stores (for example, the Windows Event Log).
Next, Mark moves on to discuss Docker. He’s says that the ability to run your .NET Core apps on a lightweight and fast web server such as NGINX, inside a Docker container, is one of the killer reasons to move to and embrace the Linux platform as a .NET Developer. Mark first gives the background of “what is docker?” They’re “containers” which are like small, light-weight VM’s (Virtual Machines). The processes within them run on the host OS, but they’re isolated from other processes in other containers. Docker containers use a “layered” file system. What this means is that Docker containers, or “images” which are the blueprints for a container instance can be layered on top of each other. So, we can get NGINX as a Docker image - which can be a “base” image but upon which you can “layer” additional images of your own, so your web application can be a subsequent layered image which together form a single running instance of a Docker container, and you get a nice preconfigured NGINX instance from the base container for free! Microsoft even provide a “base” image for ASP.NET Core which is based upon Debian 8. Mark suggests using jwilder/nginx-proxy as the base NGinX image. Mark talks about how IIS is the de-facto standard web server for Windows, but nowadays, NGinX is the de-facto standard for Linux. We need to use NGinX as Kestrel (the default webserver for ASP.NET Core) is not a production webserver and isn’t “hardened”. NGinX is a production web server, hardened for this purpose.
To prevent baking configuration settings in the Docker image (say database connections) we can use Docker Compose. This allows us to pass in various environment settings at the time when we run the Docker container. It uses YAML. It also allows you to easily specify the various command line arguments that you might otherwise need to pass to Docker when running an image (i.e. -p 5000:5000 - which binds port 5000 in the Docker image to port 5000 on the localhost).
Mark then shows us a demo of getting an ELK stack (Elastic Search, LogStash & Kibana) up and running. The ASP.NET Core application can simply write it’s logs to its console, which on Linux, is STDOUT. There is then a LogStash input processor, called Gelf, that will grab anything written to STDOUT and process it and store it within LogStash. This is then immediately visible to Kibana for visualisation!
Mark concludes that, ultimately, the main benefits of the “new way” with .NET and ASP.NET Core are the same as the fundamental benefits of the whole Linux/Unix philosophy that has been around for years. Compose your applications (and even you OS) out of many small programs that are designed to do only one thing and to do it well.

After Mark’s session, which slightly overran, it was time for lunch. Lunch at DDD 11 was superb. I opted for the chicken salad rather than a sandwich, and very delicious (and filling) it was too, which a large portion of chicken contained within. This was accompanied by some nice crisps, a chocolate bar, an apple and some flavoured water to wash it all down with!
I ate my lunch on the steps just outside the building, however, the imminently approaching rain soon started to fall and it put a stop to the idea of staying outside in the fresh air for very long!

That didn’t matter too much as not long after we’d managed to eat our food we were told that the ubiquitous “grok talks” would be starting in one of the conference rooms very soon.
I finished off my lunch and headed towards the conference room where the grok talks were being held. I was slightly late arriving to the room, and by the time I had arrived all available seating was taken, with only standing room left! I’d missed the first of the grok talks, given by Rik Hepworth about Azure Resource Templates however, I’d seen a more complete talk given by Rik about the same subject at DDD North the previous year. Unfortunately, I also missed most of the following grok talk by Andrew Fryer which discussed Power BI, a previously stand-alone product, but is now hosted within Azure.
I did catch the remaining two grok talks, the first of which was Liam Westley’s “What is the point of Microsoft?” Liam’s talk is about how Microsoft is a very different company today to what it was only a few short years ago. He starts by talking about how far Microsoft has come in recent years, and how many beliefs today are complete reversals of previously held positions – one major example of this is Microsoft’s attitude towards open source software. Steve Ballmer, the previous Microsoft CEO famously stated that Linux was a “cancer” however, the current Microsoft is embracing Linux on both Azure and for it’s .NET Development tools. Liam states that Microsoft’s future is very much in the cloud, and that they’re investing heavily in Azure. Liam shows some slides which acknowledge that Amazon has the largest share of the public cloud market (over 50%) whilst Azure only currently has around 9%, but that this figure is growing all the time. He also talks about how Office 365 is a big driver for Microsoft's cloud and that we should just accept that Office has “won” (i.e. better than LibreOffice, OpenOffice etc.). Liam wraps up his quick talk with something rather odd – a slide that shows a book about creating cat craft from cat hair!
The final grok talk was by Ben Hall, who introduced us very briefly to an interesting website that he’s created called Katacoda. The website is an interactive learning platform and aims to help developers learn all about new and interesting technologies from right within their browser! It allows developers to test out and play with a variety of new technologies (such as Docker, Kubernetes, Git, CoreOS, CI/CD with Jenkins etc.) right inside your browser in an interactive CLI! He says it’s completely free and that they’re improving the number of “labs” being offered all the time.

After the grok talks, there was a little more time to grab some refreshments prior to the first session of the afternoon, and penultimate session of the day, João “Jota” Pedro Martins’ “Azure Service Fabric and the Actor Model”. Jota’s session is all about Azure Service Fabric, what it is and how it can help you with distributed applications in the cloud. Azure Service Fabric is a PaaS v2 (Platform As A Service) which supports both stateful and stateless services using the Actor model. It’s a platform for applications that are “born in the cloud”. So what is the Actor Model? Well, it’s a model of concurrent computation that treat “actors” – which are distinct, independent units of code – as the fundamental, core primitives of an application. An application is composed of numerous actors, and these actors communicate with each other via messages rather than method calls. Azure Service Fabric is built into Azure, but it’s also downloadable for free and can be used not only within Microsoft’s Azure cloud, but also inside the clouds of other providers too, such as Amazon’s AWS.

Azure Service Fabric is battle hardened, and has Microsoft’s long-standing “Project Orleans” at it’s core.
The “fabric” part of the name is effectively the “cluster” of nodes that run as part of the service fabric framework, this is usually based upon a minimum configuration of 1 primary node with at least 2 secondary nodes, but can be configured in numerous other ways. The application’s “actors” run inside these nodes and communicate with each other via message passing. Nodes are grouped into replica sets and will balance load between themselves and failover from one node to another if a node becomes unresponsive, taking “votes” upon who the primary node will be when required. Your microservices within Service Fabric can be any executable process that you can run, such as an ASP.NET website, a C# class library, even a NodeJS application or even some Java application running inside a JVM. Currently Azure Service Fabric doesn’t support Linux, but support for that is being developed.
Your microservices can be stateless or stateful. Stateless services are simply as there’s no state to store, so messages consumed by the service are self-contained. Stateful services can store state inside of Service Fabric itself, and Service Fabric will take care of making sure that the state data stored is replicated across nodes ensuring availability in the event of a node failure. Service Fabric clusters can be upgraded with zero downtime, you can have part of the cluster responding to messages from a previous version of your microservice whilst other parts of the cluster, those that have already had the microservices upgraded to a new version, can process messages from your new microservice versions. You can create a simple 5 node cluster on your own local development machine by downloading Azure Service Fabric using the Microsoft Web Platform Installer.

Jota shows us a quick demo, creating a service fabric solution within Visual Studio. It has 2 projects within the solution, one is the actual project for your service and the other project is effectively metadata to help service fabric know how to instantiate and control your service (i.e. how many nodes within cluster etc.). Service Fabric exposes a Reliable Services API and built on top of this is a Reliable Actors API. It’s by implementing the interfaces from the Reliable Actors API that we create our own reliable services. Actors operate in an asynchronous and single-threaded way. Actors act as effectively singletons. Requests to an actor are serialized and processed one after the other and the runtime platform manages the lifetime and lifecycle of the individual actors. Because of this, the whole system must expect that messages can be received by actors in a non-deterministic order.
Actors can implement timers (i.e. perform some action every X seconds) but “normal” timers will die if the Actor on a specific node dies and has to fail over to another node. You can use a IActorReminder type reminder which effectively allow the same timer-based action processing but will survive and continue to work if an Actor has to failover to another node. Jota reminds us that the Actor Model isn’t always appropriate to all circumstances and types of application development, for example, if you have some deep, long-running logic processing that must remain in memory with lots of data and state, it’s probably not suited to the Actos Model, but if your processing can be broken down into smaller, granular chunks which can handle and process the messages sent to them in any arbitrary order and you want to maximize easy scalability of your application, the Actors are a great model. Remember, though, that since actor communicate via messages – which are passed over the network – you will have to contend with some latency.

Service Fabric contains an ActorProxy class. The ActorProxy will retry failed sent messages, but there’s no “at-least-once” delivery guarantees - if you wish to ensure this, you'll need to ensure your actors are idempotent and can receive the same message multiple time. It's also important to remember that concurrency is only turn-based, actors process messages one at a time in the order they receive them, which may not be the order they were sent in. Jota talks about the built-in StateManager class of Service Fabric, which is how Service Fabric deals with persisting state for stateful services. The StateManager has “"GetStateAsync and SetStateAsync methods which allow stateful actors to persist any arbitrary state (so long as it’s serializable). One interesting observation of this is that the state is only persisted when the method that calls SetStateAsync has finished running. The state is not persisted immediately upon calling the SetStateAsync method!
Finally, Jota wraps up his talk with a brief summary. He mentions how Service Fabric actors have behaviour and (optionally) state, are run in a performant, enterprise-ready scalable environment and are especially suited to web session state, shopping cart or any other scenarios with independent objects with their own lifetime, state and behaviour. He does say that existing applications would probably need significant re-architecture to take advantage of Service Fabric, and that the Service Fabric API has some niggles which can be improved.

After João’s session, there’s time for one final quick refreshments break, which included a table full of various crisps, fruit and chocolate which had been left over from the excess lunches earlier in the afternoon as well as a lovely selection of various individually-wrapped biscuits!
Before long it was time for the final session of the day, this was Joseph Woodward’s “Building Rich Client Applications with AngularJS2”
Joe’s talk first takes us through the differences between AngularJS 1 and 2. He states that, when AngularJS1 was first developed back in 2010, there wasn’t even any such thing as NodeJS! AngularJS 1 was great for it’s time, but did have it’s share of problems. It was written before ECMAScript 6/2015 was a de-facto standard in client-side scripting therefore it couldn’t benefit from classes, modules, promises or web components. Eventually, though, the world changed and with both the introduction and ratification of ECMAScript 6 and the introduction of NodeJS, client side development was pushed forward massively. We now had module loaders, and a component-driven approach to client-side web development, manifested by frameworks such as Facebook’s React that started to push the idea of bi-directional data flow.
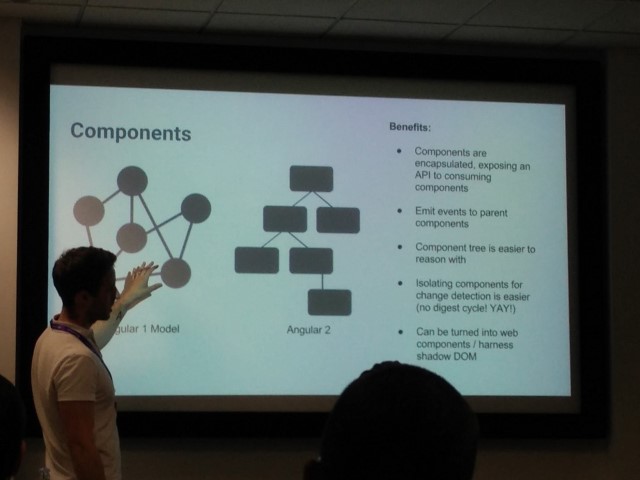
Joe mentions how, with the advent of Angular2, it’s entire architecture is now component based. It’s simpler too, so the controllers, scopes and directives of Angular1 are all now replaced with Components in Angular2 and the Services and Factories of Angular1 are now just Services in Angular2. It is much more modular and has first class support for mobile, the desktop and the the web, being built on top of the EMCAScript 6 standard.
Joe mentions how Angular2 is written in Microsoft’s TypeScript language, a superset of JavaScript, that adds better type support and other benefits often found in more strongly-typed languages, such as interfaces. He states that, since Angular2 itself is written in TypeScript, it’s best to write your own applications, which target Angular2, in TypeScript too. Doing this allows for static analysis of your code (thus enforcing types etc.) as well as elimination of dead code via tree shaking which becomes a huge help when writing larger-scale applications.
Joe examines the Controller model used in Angular1 and talks about how controllers could communicate arbitrarily with pretty much any other controller within your application. As your application grows larger, this becomes problematic as it becomes more difficult to reason about how events are flowing through your application. This is especially true when trying to find the source of code that performs UI updates as these events are often cascaded through numerous layers of controllers. In Angular2, however, this becomes much simpler as the component structure is that of a tree. The tree is evaluated starting at the top and flowing down through the tree in a predictable manner.

In Angular2, Services take the place of the Services and Factories of Angular1 and Joe states how they’re really just JavaScript classes decorated with some additional attributes. Joe further discusses how the very latest Release Candidate version of Angular2, RC6, has introduced the @NgModule directive. NgModules allow you to build your application by acting as a container for a collection of services and components. These are grouped together to for the module, from which your application can be built as a collection of one or more modules. Joe talks about how components in Angular2 can be “nested”, allowing one parent component to contain the definition of further child components. Data can flow between the parent and child components and this is all encapsulated from other components “outside”.
Next, Joe shows us some demos using a simple Angular2 application which displays a web page with a textbox and a number of other labels/boxes that are updated with the content of the textbox when that content changes. The code is very simple for such a simple app, however, it shows how clearly defined and structured an Angular2 application can be. Joe then changes the value of how many labels are created on the webpage to 10000 just to see how Angular2 copes with updating 10000 elements. Although there’s some lag, as would be expected when performing this many independent updates, the performance isn’t too bad at all.

Finally, Joe talks about the future of Angular2. The Angular team are going to improve static analysis and ensure that only used code and accessible code is included within the final minified JavaScript file. There’ll be better tooling to allow generation of many of the “plumbing” around creating an Angular2 application as improvements around building and testing Angular2 applications. Joe explains that this is a clear message that Angular2 is not just a framework, but a complete platform and that, although some developers are upset when Angular2 totally "changed the game" with no clear upgrade path from Aungular1, leaving a lot of A1 developers feeling left out, Google insist that Angular2 is developed in such a way that it can evolve incrementally over time as web technologies evolve and so there shouldn’t be the same kind of wholesale “break from the past” kind of re-development in the future of Angular as a platform. Indeed, Google themselves are re-writing their AdWords product (an important product generating significant revenue for Google) using their own Dart language and using Angular2 as the platform. And with that, Joe’s session came to an end. He was so impressed with the size of his audience, though, that he insisted on taking a photo of us all, just to prove to his wife that we was talking to a big crowd!
After this final session of the day it was time for all the attendees to gather in the communal area for to customary “closing ceremony”. This involved big thanks to all of the sponsors of the event as well as prize draw for numerous goodies. Unfortunately, I didn’t win anything in the prize draws, but I’d had a brilliant time at my first DDD in Reading. Here’s hoping that they continue the “original” DDD’s well into the future.

UPDATE: Kevin O’Shaughnessy has also written a blog post reviewing his experience at DDD 11, which is an excellent read. Apart from the session by Mark Rendle, Kevin attended entirely different sessions to me, so his review is well worth a read to get a fuller picture of the entire DDD event.
